

Getting Started with Kubernetes


Introduction
Kubernetes or k8s for short is an open source container orchestrator originally developed by the engineers at Google. Kubernetes solves many problems of using the Microservice Architecture in production. It automatically takes care of scaling, self-healing, load-balancing, rolling updates, and other tasks that used to be done manually by system administrators
Due to the rise in the use of the Microservices architecture as well as packaging applications in a self contained entity, it becomes imperative to be able to manage these containers dynamically in production - This is where the power of Kubernetes comes to light.
In this article you will understand what Kubernetes is all about, how it can be useful to you and some concepts at a high level.
Prerequisites
Docker and Kubernetes
Docker and Kubernetes are complementary technologies. When Kubernetes orchestrates the new deployment(you will learn about deployments in the coming sections), it instructs docker or the container runtime to fire up specified containers. The advantage of Kubernetes is that it will automatically determine how to schedule and distribute pods(you will also learn about this soon) instead of manually doing these things. Kubernetes is the orchestrator(like the director) while docker is the container runtime engine.
It is noteworthy to mention that there are other container orchestration tools like Docker swarm, Apache Mesos etc but Kubernetes is highly used because of the large community behind it. As of the time of the writing, Kubernetes have over 80,798 commits and over 2,206 active contributors to the repository on Github
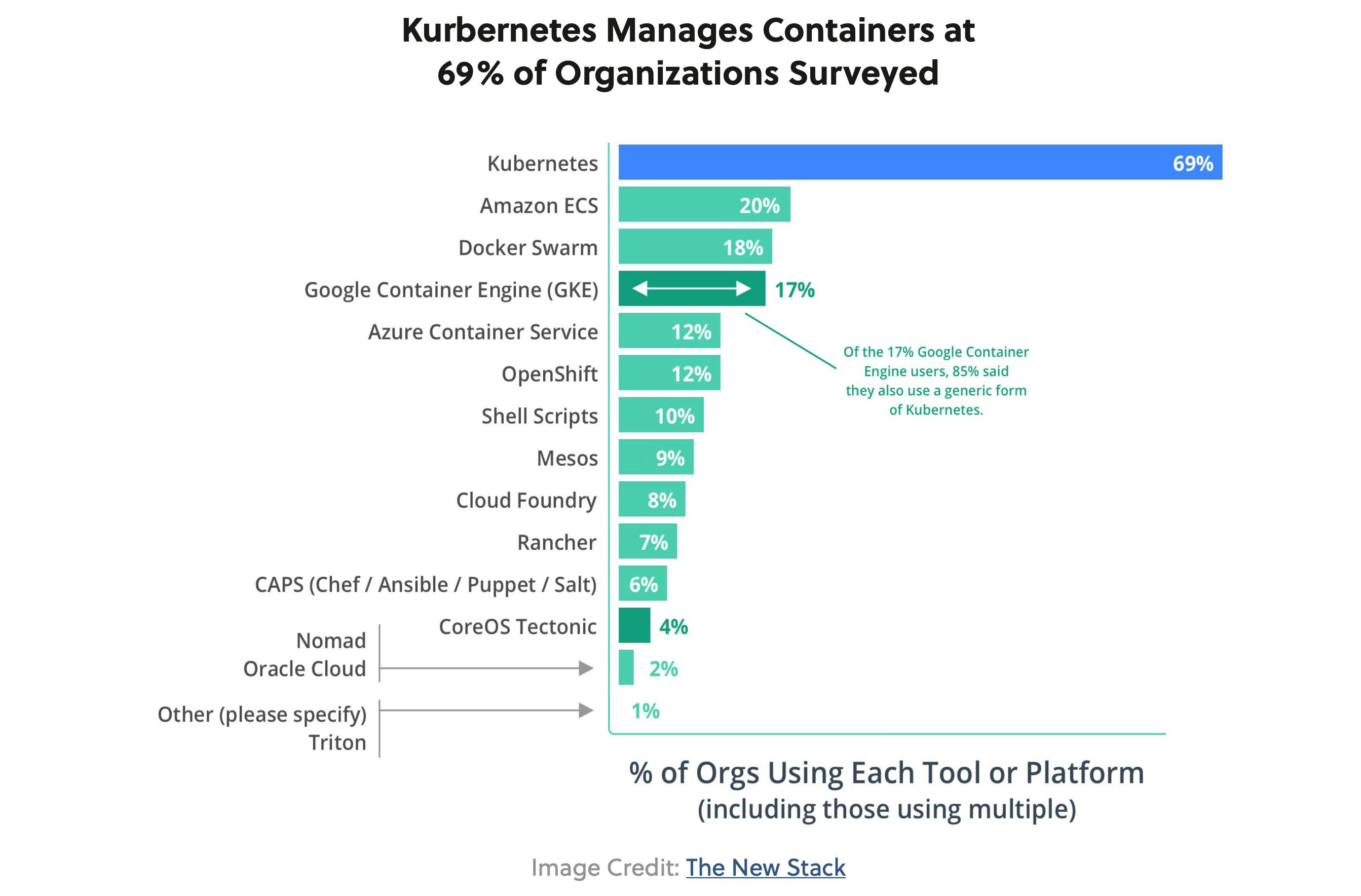
The main strength of Kubernetes is the thriving open-source community led by Google, Red Hat, and CoreOS . It is one of the top open-source projects on GitHub .
How is Kubernetes Useful to Me
Very few companies run at the scale of Google, Netflix, and Spotify, cycling through millions of containers . But even for the rest, as you scale the number of containers from a handful to even several tens or hundreds of containers, the need for a container orchestrator becomes clear .
Coupled with the continued rise of cloud computing, Kubernetes serves as a single interface through which to request data-center resources
Kubernetes Components
At a high level, Kubernetes works similarly to many cluster architectures. It consists of one or more masters and several nodes they can control. The master node orchestrates the applications running on nodes and they constantly monitor to ensure they match the desired state set in the configuration.
So the Kubernetes Cluster can largely be divided into Master and Node Components
Master Components
Master components globally monitor the cluster and respond to cluster events . These can include scheduling, scaling, or restarting an unhealthy pod . Five components make up the Master components: kube-apiserver, etcd, kube-scheduler, kube-controller-manager, and cloud-controller-manager
kube-apiserver: REST API endpoint to serve as the frontend for the Kubernetes control plane
etcd: Key value store for the cluster data (regarded as the single source of truth)
kube-scheduler: Watches new workloads/pods and assigns them to a node based on several scheduling factors (resource constraints, anti-affinity rules, data locality, etc .)
kube-controller-manager: Central controller that watches the node, replication set, endpoints (services), and service accounts
cloud-controller-manager: Interacts with the underlying cloud provider to manage resources
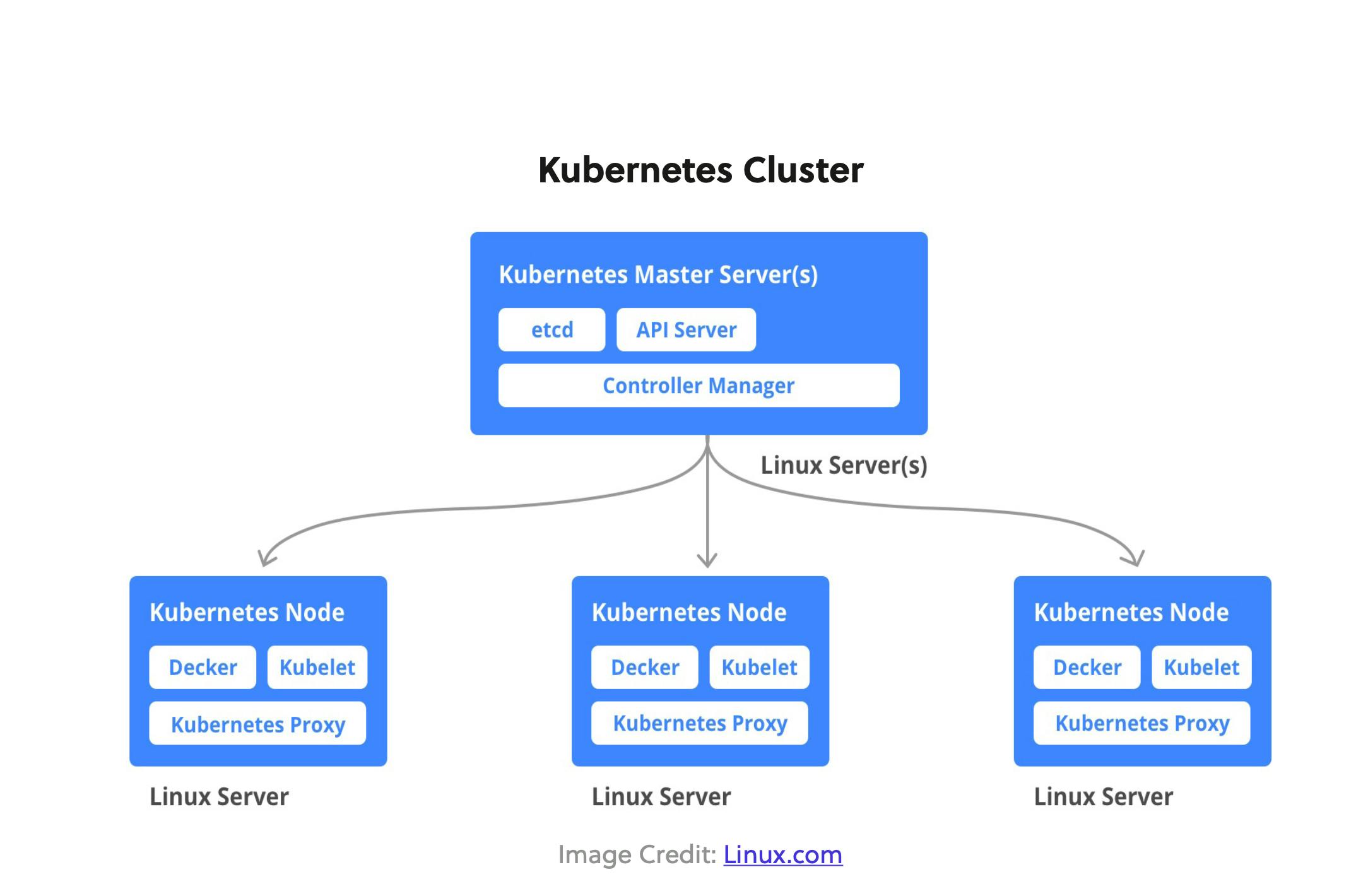
Node Components
Unlike Master components that usually run on a single node (unless High Availability Setup is explicitly stated), Node components run on every node .
kubelet: Agent running on the node to inspect the container health and report to the master as well as listening to new commands from the kube-apiserver
kube-proxy: Maintains the network rules
container runtime: Software for running the containers (e .g . Docker, rkt, runc)
Kubernetes Object Management Model
Before talking about Kubernetes Workloads like pods, controllers etc, It's imperative to understand Kubernetes Object Management model. There are two main ways to manage object configuration - Declarative and Imperative.
In this article, You'll focus briefly on the Declarative mode. You can learn more about the other mode here.
Declarative Object Management

In essence, when you write YAML or JSON files, you describe the desired state of the application: what Docker image should run, what scaling strategy to use, and what ports/services to expose . This information is posted to the kube-api-server, and the master node distributes the work to ensure that the cluster matches the desired state . This configuration is stored in etcd, and the workload is deployed onto the cluster . Finally, Kubernetes will constantly check to see whether the current state of the cluster matches the desired behavior the programmer has defined . So, if a pod dies, Kubernetes will fire up another one to match the desired state .
While this all sounds simple (and that was part of the intent), it is a powerful scheme that makes Kubernetes very useful . You (the programmer) only have to specify the desired state, and Kubernetes will take care of the rest (instead of having you run specific commands to achieve this like in imperative models) .
According to the Kubernetes documentation, a Kubernetes object should be managed using only one technique. Mixing and matching techniques for the same object results in undefined behavior. You can learn more about the management techniques here
Kubernetes Workloads
Kubernetes workloads are divided into two major components: pods (the basic building block) and controllers (e .g . ReplicaSet, Deployment, StatefulSet, CronJob, etc .)
Pods
A Pod for Kubernetes is what a container is for Docker: the smallest and simplest unit in its object model . It is helpful to conceptualize Pods as a single instance of an application—or a container . In reality, a Pod encapsulates one or more containers as well as storage resources, an IP address, and rules on how the container(s) should run .
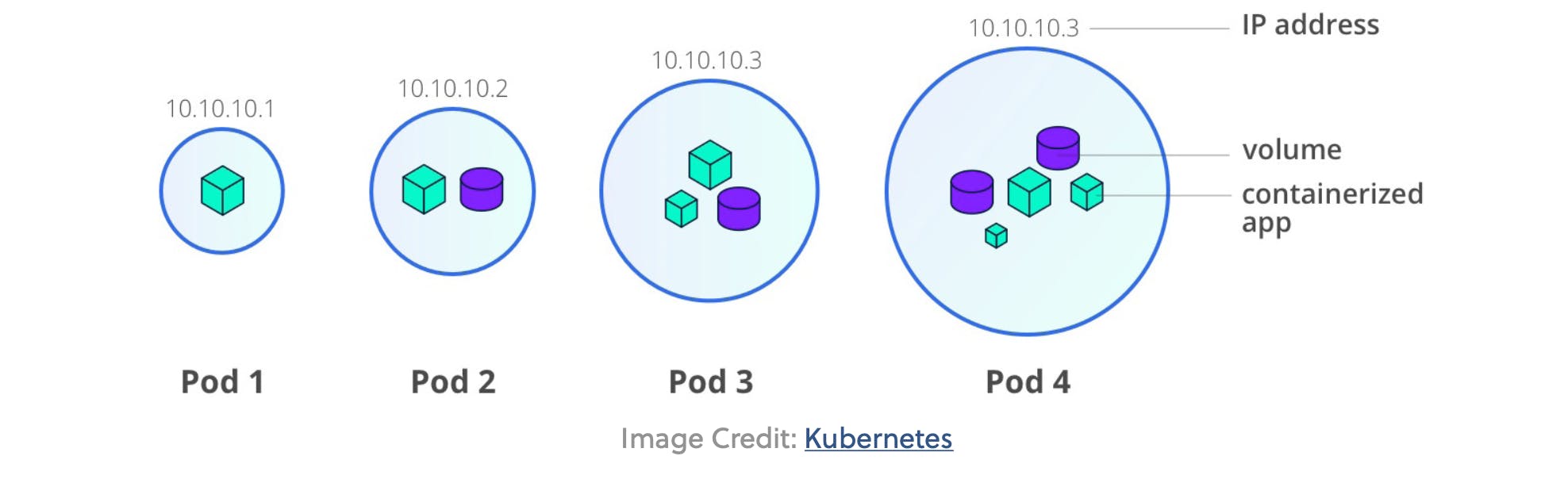
As Pods are meant to be an atomic unit in Kubernetes, each Pod should really run a single instance of a given application . So, if you need to run multiple copies of a container, each container should run in its own Pod instead of having all of those containers be in a single Pod . However, sometimes a multi-container Pod makes sense if they are closely-related
(a common example is some logging component) . One key thing to note is that all the containers in a Pod will share the same environment: memory, volumes, network stack, and most importantly, the IP address . In a typical deployment, Pods are not directly created by the programmer . Instead, the Controller will schedule a Pod to run on a Node . Some important things to know about Pods:
- A Pod can only exist on a single Node
- A Pod can never be in a partially-deployed state . If a part of the Pod never comes up, it is considered unhealthy and fails .
- A Pod is not “healed” but rather treated as a disposable component . In other words, if a Pod becomes unhealthy, Controller elements will kill the Pod and start up another Pod, replacing rather than healing it .
Controllers
As mentioned earlier, Pods are usually deployed indirectly via Controllers . The one used most frequently is Deployments, but we will quickly cover some other types of Controllers .
ReplicaSet
ReplicaSet, as the name suggests, deploys the specified replicas of the Pod . Unless you require custom updates to the Pods, it is recommended to use Deployments, which are higher level objects that wrap around ReplicaSets .
Deployments
Deployments allow for rolling updates and easy rollbacks on top of ReplicaSets . You can define the desired state in the Deployment model, including scaling, rolling updates in canary or blue/ green fashion, and Deployments will take care of it for you .
StatefulSets
StatefulSets are similar to Deployments, but it maintains a “sticky identity” for each of the Pods . It is useful for applications in which a stable network identifier or persistent storage is required . A common example would be ElasticSearch .
CronJobs
CronJob manages time-based jobs. A common example would be sending out daily reports or cleaning up old data .
Conclusion
Kubernetes has been the de-facto standard for container orchestration and has come to stay due to its heavy backing by the community.
In this article you have learnt What Kubernetes is, How it can be useful to you, the architecture of a Kubernetes cluster and some basic concepts to get you up and running. You can learn more about getting started with Kubernetes from the official documentation